Construct a Simple Bible Search Tool - Part 1
When HPCCSystems launched ECL as a Virtual Machine I knew the first task I wanted to attempt: the Bible Search program. This was the program that got me into data processing back in 1988 when processing 6MB of text on my PC with a 20MB hard disk was a 'Big Data' problem. Since 1988 I have re-written the code in more than a dozen different languages for different reasons and today I have photographs that take more space than the Bible. Still I would argue that if Big Data is going to live up to its potential then we need to know rather more about Big Data than simply the fact it is 'Big'. Searching is just a very simple start; but I would be very skeptical of any system that cannot at least do that.
Getting the Data in HPCC
First task was to find a suitable Bible text to use. I selected the KJV as it is free from copyright outside of the UK and it is really available in many place. I actually selected a download with a slightly painful format; this is not just masochism - it allows us to look at some of the nastiness involved in using data that wasn't prepared for you. The link is: http://av1611.com/ and at least as of June 2011 the link to the raw text file (zipped) was in the bottom left corner.
First the file was downloaded and unzipped (using regular Windows): then the first task was to make it available to ECL. This involves first uploading the file to the 'landing zone' and then 'spraying' the file from the landing zone to Thor.
This may seem unnecessarily complicated, and frankly for a pure VM it is; the 'upload' simply copies the data from one part of your disk to another and then the 'spray' copies it again! This multi-step process makes far more sense once you are in an enterprise environment and have one or more multi-node Thors.
In this situation the 'landing zone' is really a breakwater or interface to the outside world. The machines in 'HPCC land' can be completely isolated on the network and they only have visibility to the landing zone. Equally other systems (and we've done this with main-frames, rdbms, ftp and all sorts of other mechanisms) don't need to know about the HPCC; they simply have to get their data to the landing zone. The 'upload' is thus really a 'non-HPCC' process that makes the data available to the HPCC.
The spray is rather different; data in a single file (and possibly some very alien format) now has to be split into records, distributed across all the nodes of a Thor, replicated (if that is in force) and then declared to the ECL metadata management system (Dali). In a production environment it is not uncommon to have the spray driven from ECL code and even to use the ECL Event/Workflow system to trigger the ECL code upon arrival of a file. But that is another project; for our purposes I just followed the training manual and had the data available in < 5 minutes.
Smacking the Data into Shape
Actually viewing the data in HPCC is extremely simple (especially as I knew it was in CSV format with cr/lf record breaks).

Defines a very simple format to treat each line as a complete string; there are actually simpler ways to do just this - but I know where the code is headed The result should be:

We have the data in hand and it looks about right; however the warning bells should be sounding. Each line is a separate record; but if you look the verse reference and the verse appear on alternating lines. You can store data that way; but it is very unwise. Generally you want every record to be atomic; that is to say that all the information required to process the record (at least lexically) should be in the record. Now you can tackle that later, as and when the need arises, but a key premise of ECL is that early work is hard to make late work easy. So let's clear up this record structure immediately; we can use a ROLLUP with a slightly clever ROLLUP expression:

Those of you familiar with map-reduce probably think of a ROLLUP as a reduce; and with simple expressions it is. This is very different. The file came in order and within that order I have a reference of the form $$ Book Chapter:Verse followed by another record with the verse text. I can use that pattern in the sequence of the file to define when the rollup should occur[1]. The code above would gather any number of 'text' lines onto the preceding verse reference (although in this file only one line follows). The data now looks like this:

The next task was simple but is an important logical step forward. I currently have text - I can read it and know what it is; but from the ECL perspective I just have lines. If I want to do processing intelligently then I need to start migrating from text to semi-structured data. As a first cut I simply want to pull the book / chapter / verse information out into separate columns. Fortunately the ECL String library has quite a few nifty little functions for doing just that.
If the table t is now viewed it looks like:
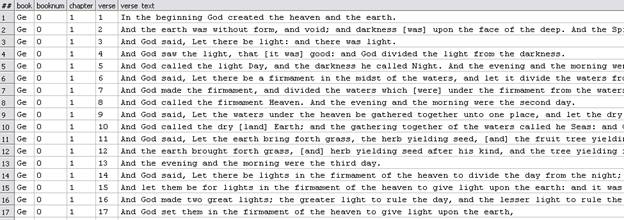
Things are looking a lot cleaner but the sharp-eyed may have noted that the booknum field is all zeros. The book number was not provided in the text and therefore it is still blank. I could fill it in quite easily by doing a small amount of manual work. I could write a piece of ECL to find all the book names, enumerate them and then type in a MAP statement to map from the book name to the book number; at least I could if I didn't have a moral aversion to manual work. Instead I use the ITERATE function to step through the verses pair by pair incrementing the book number if the bookname changes! (Actually there is another way to do this - see here)

Iterate is a very alien feature to map-reducers; it takes advantage of the fact that the entire dataset has an order. It steps through the data moving forward one record at a time but taking the current (RIGHT) and previous (LEFT) record into account[2].
All the above done, we can declare success: ETL complete - the data is now in shape.

Organization and Structure
Writing this document has taken far longer than writing the code. I had hacked all the code above into a builder window and got it running inside ten minutes. The temptation to keep hacking is strong; but ECL is really designed for a longer term view of things. Once you have the data up and visible it is usually a good idea to step back and plan for the longer haul. If I am planning to build more and more code around this item of data (and I do) then I should structure my code to make that easy. I also want to plan so that if I decide to use one of the other KJV downloads, or use a different version, as little code as possible has to change. The easiest, quickest way to do that is to encapsulate all the code related to this particular format into one module[3]. The code for the full module is below; although parts of it have not been explained yet.
import Std.Str AS *;
EXPORT File_KJV := MODULE // Note - this will NOT work well in a distributed system as it requires iterates and rollups // that stream from one node to the next. // Of course - this file processes in almost no-time on a laptop - so multi-node should not be an issue R := RECORD STRING Txt; END;
d := DATASET('kjv_text',R,CSV(SEPARATOR('')));
R TextOntoReference(R le, R ri) := TRANSFORM SELF.Txt := le.Txt + ' ' + ri.Txt; END;
Rld := ROLLUP(d,LEFT.Txt[1]='$' AND RIGHT.Txt[1]<>'$',TextOntoReference(LEFT,RIGHT));
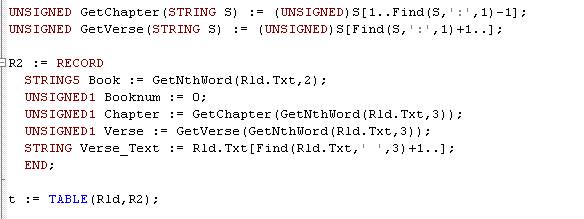
UNSIGNED GetChapter(STRING S) := (UNSIGNED)S[1..Find(S,':',1)-1]; UNSIGNED GetVerse(STRING S) := (UNSIGNED)S[Find(S,':',1)+1..];
R2 := RECORD STRING5 Book := GetNthWord(Rld.Txt,2); UNSIGNED1 Booknum := 0; UNSIGNED1 Chapter := GetChapter(GetNthWord(Rld.Txt,3)); UNSIGNED1 Verse := GetVerse(GetNthWord(Rld.Txt,3)); STRING Verse_Text := Rld.Txt[Find(Rld.Txt,' ',3)+1..]; END;
t := TABLE(Rld,R2);
R2 NoteBookNum(R2 le, R2 ri) := TRANSFORM SELF.Booknum := IF( le.book=ri.book, le.booknum, le.booknum+1 ); SELF := ri; END;
EXPORT Txt := ITERATE(t,NoteBookNum(LEFT,RIGHT));
EXPORT Key := INDEX(Txt,{BookNum,Chapter,Verse},{Verse_Text},'~key::kjv_txt');
EXPORT Bld := BUILDINDEX(Key,OVERWRITE);
EXPORT Layout_Reference := RECORD UNSIGNED1 BookNum; UNSIGNED1 Chapter; UNSIGNED1 Verse; END;
EXPORT Get(UNSIGNED1 pBookNum,UNSIGNED1 pChapter, UNSIGNED1 pVerse) := FUNCTION RETURN Key(BookNum=pBookNum,pChapter=0 OR pChapter=Chapter,pVerse=0 OR pVerse=Verse); END;
EXPORT GetBatch(DATASET(Layout_Reference) refs) := FUNCTION RETURN JOIN(refs,Key,LEFT.BookNum=RIGHT.BookNum AND LEFT.Chapter=RIGHT.Chapter AND LEFT.Verse=RIGHT.Verse,TRANSFORM(RIGHT)); END;
END;
If you hunt out the part 'EXPORT Txt :=' all of the code prior to that point should be familiar; all I have done is wrap it inside a module.
Preparing the Core Data for Roxie
So, having ETL'd the data and given ourselves a coding structure, what is the next step? For me the next step is to get the core (or 'raw') data available inside Roxie so that it can be delivered to users using a UI (and not ECL). This is as easy as building an index, or rather, in our new structured world: providing the exports to allow the index to be built.
Whilst not required by ECL I have a convention that states that if I have a module wrapped around a dataset (and I usually do) then the principal key built from that dataset is called 'Key'. Further all the keys for a module should be buildable from a label 'Bld[4]'.
The module also exports a layout for the book-number, chapter number, verse number triple. Eventually I would expect that layout to split into a separate layout module that was shared between multiple datasets; however my general rule is that I don't abstract until the second time I need something[5].
The final task for this module is to allow the data to be fetched. Again keeping my interfaces simple I give myself an attribute Get that takes the book number, chapter and verse as parameters and returns the verses in question.

This shows that a Roxie index fetch is extremely simple; you simply name the index and filter it; the way you would a file in Thor. In fact I added some complexity here; I decided that I could make my function more general purpose by defining that a zero for the verse would return the whole chapter and a zero for the chapter and verse would return the whole book[6].
For a task as simple and fast as this the above would be adequate. However, in general it is always better to provide a batch interface to a Get as well. This allows for a number of different records to be retrieved from the dataset in a streaming fashion; this does not reduce the work the Roxie does but it can reduce latency.

This may look like a regular THOR join; it is supposed to; however many old Roxie hands refer to it as a 'half-keyed join'. For every record within refs a separate index fetch is executed and the results returned. This is the function which will eventually fetch the data once a search has constructed a list of interested verses.
So where are we now?
The astute will note that we cannot actually search the Bible yet! What we have done is ingest the KJV Bible in a fairly nasty form and convert it into relatively well structured records. We have then constructed Roxie indexes and code that will be able to retrieve Bible verses given one or more references. Finally we have wrapped all the ETL and retrieval code into a single module with 'standardized' export labels so that we could 'plug' our KJV source file into a larger system without the author of the larger system having to know any of the 'dirt' we got up to.
In part II the 'author of the larger system' (that also happens to be me!) will use this module to actually construct the search.